- Turns websites into clean, LLM-ready Markdown
- Supports actions like clicking, scrolling, and filling forms
- Free 500-credit plan with no card required
- Concurrent request limits can slow large jobs
- Interactive actions aren’t always fully reliable
- Timeout limits can break scrapes on slow websites
In this article, we will cover:
- What Firecrawl is and how it works
- Core features and API endpoints
- Pricing breakdown
- Best use cases
- Limitations and drawbacks
- How it compares to alternatives
- Final verdict
What is Firecrawl?
Firecrawl is a web scraping API developed by Mendable.ai (Y Combinator S22) that converts websites into clean, structured data optimized for AI applications. Unlike traditional scrapers that rely on brittle CSS selectors or XPath expressions, Firecrawl uses AI to understand page context and extract content intelligently.
The platform launched in 2024 and has quickly gained traction with over 7 million downloads on npm and 105+ contributors on GitHub. It positions itself as “The Web Data API for AI,” specifically designed to power LLM applications, RAG systems, and AI agents.
Firecrawl is open source (AGPL-3.0 license) and available for self-hosting, though the hosted cloud version offers additional features like proxy rotation and higher concurrency limits.
Core Features
Firecrawl organizes its functionality around a REST API with distinct endpoints for different scraping tasks. Beyond the basic endpoints, it includes several advanced capabilities for handling complex websites and extracting structured data.
API Endpoints
Firecrawl exposes five main endpoints:
/scrape extracts content from a single URL and returns it in multiple formats including Markdown, HTML, JSON, and screenshots. It handles JavaScript rendering automatically and can capture dynamic content without additional configuration.
/crawl recursively scrapes all accessible pages from a starting URL. It follows internal links (even without a sitemap), manages crawl depth, and returns content from every discovered page. This is useful for extracting entire documentation sites or knowledge bases.
/map quickly retrieves all URLs from a website without scraping content. This helps with URL discovery before deciding what to crawl.
/search combines web search with scraping capabilities. You pass a query, and Firecrawl returns full page content for each search result in one API call.
/extract uses AI to pull structured data based on natural language prompts or JSON schemas. Instead of writing selectors, you describe what you want (“extract all product prices and ratings”) and receive clean JSON output.
Additional Capabilities
Beyond the core endpoints, Firecrawl includes features that handle edge cases and complex scraping scenarios.
Actions let you simulate user behavior before scraping. You can click buttons, scroll pages, fill forms, and wait for elements to load. This handles content hidden behind interactions.
Media parsing supports extracting text from web-hosted PDFs, DOCX files, and other document formats.
Smart wait intelligently detects when dynamic content finishes loading, reducing failed scrapes on JavaScript-heavy sites.
FIRE-1 Agent is an AI agent that can navigate complex pages, click through pagination, handle “Load More” buttons, and solve simple CAPTCHAs automatically.
MCP Server integrates with the Model Context Protocol for direct use with AI assistants and agent frameworks.
Output Formats
Firecrawl returns data in several formats suitable for different use cases. The format you choose depends on whether you need raw content, structured data, or visual captures.
Markdown is the default output, stripping navigation, headers, footers, and other boilerplate to leave clean, readable text. This format works well for feeding content into LLMs since it preserves semantic structure while minimizing token usage.
HTML provides the raw page structure when you need it.
JSON returns structured data when combined with the extract endpoint or a defined schema.
Screenshots capture visual representations of pages at the time of scraping.
Links and metadata include title, description, and other page information.
The onlyMainContent option focuses extraction on the primary content area, filtering out sidebars and irrelevant elements.
Pricing
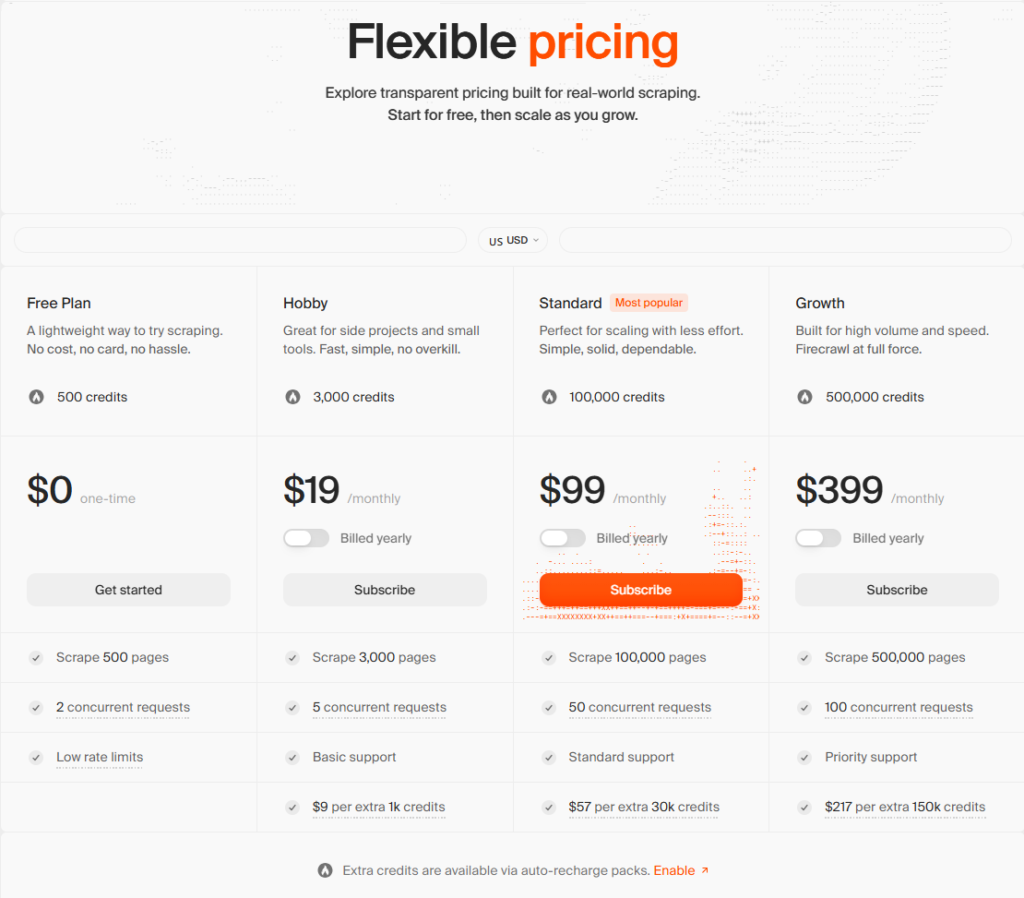
Firecrawl uses a credit-based pricing model where 1 credit equals 1 scraped page under standard conditions. This makes cost estimation straightforward compared to compute-based pricing models used by some competitors.
| Plan | Monthly Cost | Credits | Concurrent Requests | Extra Credits |
|---|---|---|---|---|
| Free | $0 | 500 (one-time) | 2 | N/A |
| Hobby | $16 | 3,000 | 5 | $9 per 1k |
| Standard | $83 | 100,000 | 50 | $47 per 35k |
| Growth | $333 | 500,000 | 100 | $177 per 175k |
| Enterprise | Custom | Unlimited | Custom | Custom |
Some features consume additional credits. LLM extraction costs 50 credits per page. Search costs 2 credits per 10 results.
The free tier provides 500 credits with no credit card required, which is enough to test the service on small projects.
Integrations
Firecrawl connects with popular frameworks and platforms across the AI and automation ecosystem. These integrations reduce the code needed to incorporate web data into existing workflows.
LLM frameworks: LangChain (Python and JavaScript), LlamaIndex, CrewAI, Camel AI, AutoGen
Low-code platforms: n8n, Make.com, Zapier, Dify, Langflow, Flowise AI
Vector databases: Works with any database through clean Markdown output
SDKs: Official support for Python and Node.js. Community SDKs exist for Go, Rust, and C#.
Best Use Cases
Firecrawl targets specific workflows where traditional scraping tools fall short. The following use cases highlight where the platform provides the most value.
RAG Systems
Firecrawl excels at gathering training data and context for retrieval-augmented generation. The clean Markdown output reduces preprocessing overhead, and the crawl endpoint can ingest entire documentation sites for knowledge bases.
AI Agents
When AI agents need current web information, Firecrawl provides real-time data extraction. The MCP server enables direct integration with agent frameworks.
Competitor Research
The search and scrape combination lets you monitor competitor websites, track pricing changes, and gather market intelligence without building custom scrapers.
Documentation Ingestion
Converting technical documentation into structured formats for chatbots or internal knowledge systems is straightforward with the crawl endpoint.
Content Migration
Moving content between CMS platforms becomes simpler when you can extract clean text from source sites.
Limitations
No tool is perfect, and Firecrawl has several constraints worth understanding before committing to it for production workloads.
Self-Hosting Concerns
The open source version is not fully production-ready. As noted on the official GitHub page, certain self-hosted endpoints behave differently from the cloud version, and some features may push users toward paid plans.
Rate Limits
Concurrent request limits can bottleneck high-volume operations. The free tier allows only 2 concurrent requests, which means jobs queue if you exceed this.
Complex Interactions
While Actions support clicking and scrolling, these interactions are not always reliable. Missing data can result from timing issues or dynamic content that loads unpredictably.
No Custom LLM Selection
Firecrawl uses a single, predefined LLM model for extraction. You cannot choose or configure a different model.
API Changes
The platform is still evolving rapidly. API endpoints changed between v1 and v2 within less than two years, which can create maintenance headaches for production applications.
Timeout Limitations
Built-in timeouts can cause failures on slow-loading websites. You cannot extend timeouts indefinitely, making Firecrawl less suitable for particularly sluggish sites.
Cost at Scale
While pricing is competitive for moderate volumes, costs add up for high-volume scraping (millions of pages). At extreme scale, self-hosted infrastructure with tools like Puppeteer or Playwright may prove more economical.
Alternatives
Several other tools compete in the AI-focused web scraping space. Each takes a different approach to the same problem, and the right choice depends on your specific requirements.
Apify
Apify is a full-stack scraping platform with thousands of pre-built scrapers called Actors. It offers more flexibility and customization options but requires more configuration. Pricing follows a compute-unit model that can be harder to predict than Firecrawl’s credit system. Apify also provides Crawlee, an open source crawling framework.
Crawl4AI
Crawl4AI is a completely free, open source alternative that runs on your own infrastructure. It offers granular control and supports local LLM models for extraction, addressing data sovereignty concerns. Performance benchmarks suggest it runs approximately 4x faster than Firecrawl for simple crawling tasks. The tradeoff is more setup and maintenance work.
Bright Data
Bright Data is an enterprise solution with the largest proxy network in the industry. It handles the most challenging anti-bot protections but comes with higher complexity and cost. Best suited for large-scale operations requiring maximum coverage.
Spider
Spider is a Rust-based crawler focused on raw speed, claiming to process thousands of pages per second. It offers good customization but requires familiarity with Rust for deep modifications.
ScrapeGraphAI
ScrapeGraphAI uses natural language for self-healing selectors that adapt when websites change. It combines AI features with user-friendly design at competitive pricing.
When Firecrawl Makes Sense
Understanding when to use Firecrawl helps avoid mismatched expectations. Here is a breakdown of scenarios where it fits well and where other options might serve better.
Firecrawl fits well when you need:
- Quick conversion of web content to LLM-friendly formats
- Minimal setup for scraping dynamic, JavaScript-heavy sites
- AI-powered extraction without writing custom parsers
- Integration with existing AI frameworks like LangChain or LlamaIndex
- A managed service that handles proxies and anti-bot measures
It may not be the right choice if you need:
- Complete control over every aspect of the crawling process
- Very high-volume scraping (millions of pages monthly)
- Advanced interactive automation beyond basic clicks and scrolls
- Guaranteed identical behavior between self-hosted and cloud versions
Final Verdict
Firecrawl delivers on its promise of simplifying web data extraction for AI applications. The API is straightforward, the Markdown output is clean, and the AI-powered extraction removes much of the tedious work involved in traditional scraping.
For developers building LLM applications, RAG systems, or AI agents that need web data, Firecrawl offers a solid balance between ease of use and capability. The free tier provides enough credits to evaluate whether it meets your needs before committing to a paid plan.
The main caveats are around scale and control. High-volume users should calculate whether credit costs make sense compared to building custom infrastructure. And developers who need fine-grained control over every crawling detail may find the abstraction limiting.
For most AI-focused use cases at moderate scale, Firecrawl is worth considering as your web data layer.